This is a sub-topic of Running on other cloud providers . See that post for why you might want to do this, and info and examples for other providers too.
This guide is a work in process.
Intro
RunPod.io (referral link) prices are “8 times cheaper” than other cloud providers. They have both a server (“pod”) and serverless offering. Signing up with the referral link directly supports docker-diffusers-api development.
Sample pricing:
-
Serverless (scale-to-zero)
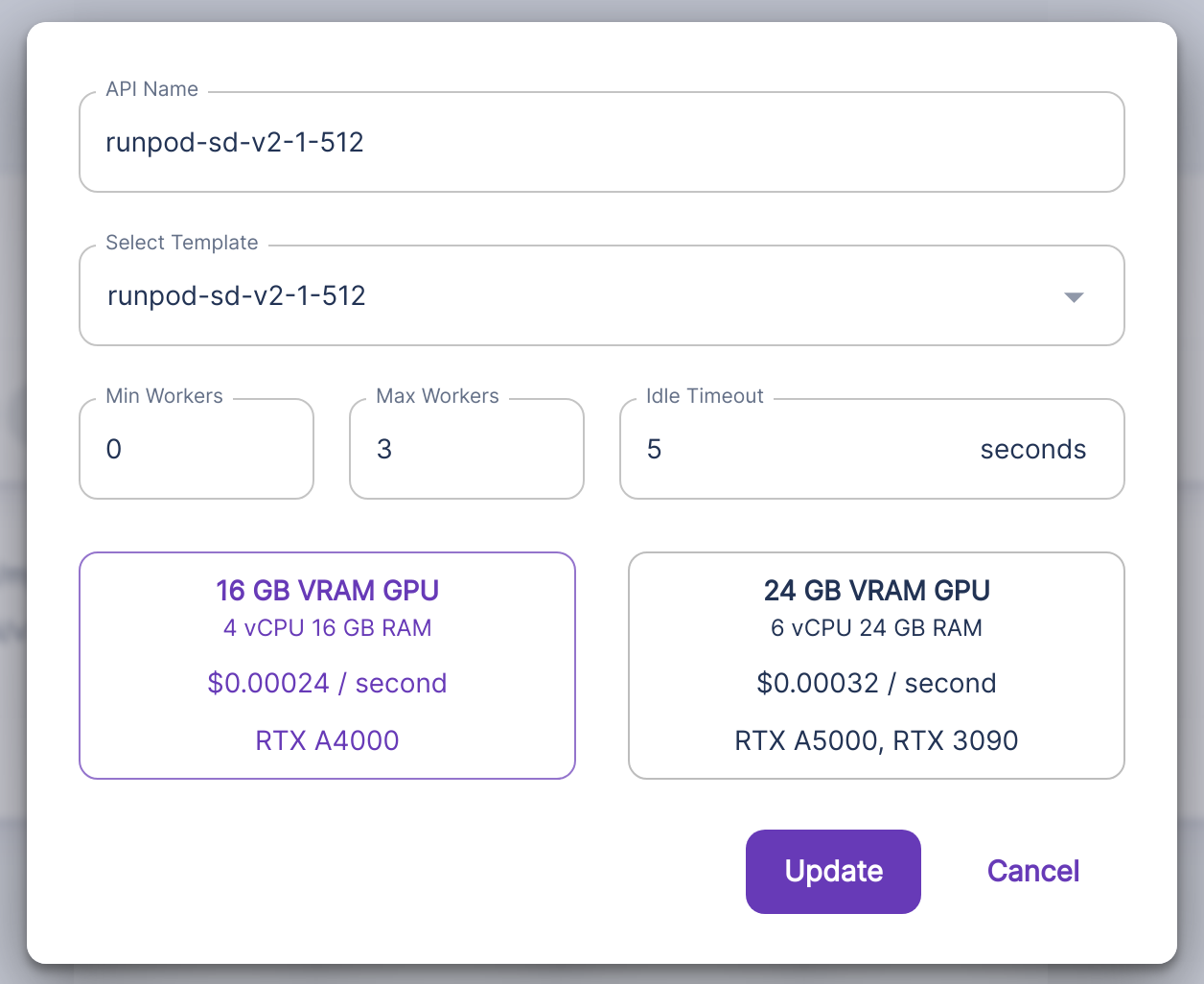
- RTX A4000, 16GB, $0.00024 / second
- RTX A5000 / 3090, 24GB, $0.00032 / second
-
Pods (long running)
- 1x RTX 3090, 24GB, 0.440/hr
- 1x A100, 80GB, $2.090/hr
- and more (secure cloud vs community pricing)
- Storage: $0.10/GB/month on running pods, $0.020/GB/month on stopped
Serverless
RunPod’s “Serverless AI” is currently in a closed beta. There is some general information that is publicly available, but for access, you should use the contact button on that page to request access.
1. Create a docker container
- Clone https://github.com/kiri-art/docker-diffusers-api-runpod.
- Set any necessary environment variables (see build.sh) and run e.g.
$ ./build.sh -t user/runpod:sd-v2-1-512 \
--build-arg MODEL_ID="stabilityai/stable-diffusion-2-1-base"
(or just use docker build as you see fit)
Your model will be downloaded at build time and be included in your final container for optimized cold starts.
Make sure HF_AUTH_TOKEN is set and that you’ve accepted the terms (if any) for your model on HuggingFace. Until the upcoming release, S3-compatible storage credentials are REQUIRED and a safetensors version of your model will be saved there
- Upload to your repository of choice, e.g.
$ docker push user/runpod:sd-v2-1-512
2. Create a Serverless AI Template
- Go to https://www.runpod.io/console/serverless/user/templates
- Click NEW TEMPLATE
- For CONTAINER IMAGE, give the details of your container above.
3. Create an API
- Go to https://www.runpod.io/console/serverless/user/apis
- Click NEW API
- For TEMPLATE, choose the template you created above.
4. Using / Testing
You need:
- Your MODEL key from the previous section (right below your API name, it looks like
"mjxhzmtywlo34j") - Your API key from https://www.runpod.io/console/user/settings (create a new one if you haven’t done so already, and store it somewhere safe; you need the full “long” string like
"Z2KDP8CSD5ZNNLIHIO0D3PY4NVI0AJCB9106XTNM")
Using our build in test.py file with the --runpod option and appropriate environment variables, e.g.
$ export RUNPOD_API_KEY="XXX"
$ export RUNPOD_MODEL_KEY="XXX"
$ python test.py --runpod txt2img
Running test: txt2img
{
"modelInputs": {
"prompt": "realistic field of grass",
"num_inference_steps": 20
},
"callInputs": {}
}
https://api.runpod.ai/v1/mjxhzmtywlo34j/run
<Response [200]>
{'id': 'd08d30b3-5536-4273-b09a-ba03304bd5d7', 'status': 'IN_QUEUE'}
Request took 19.9s (inference: 4.8s, init: 3.1s)
Saved /home/dragon/www/banana/banana-sd-base/tests/output/txt2img.png
{
"$mem_usage": 0.7631033823971289,
"$meta": {
"MODEL_ID": "stabilityai/stable-diffusion-2-1-base",
"PIPELINE": "StableDiffusionPipeline",
"SCHEDULER": "DPMSolverMultistepScheduler"
},
"$timings": {
"inference": 4836,
"init": 3060
},
"image_base64": "[512x512 PNG image, 429.8KiB bytes]"
}
Pod (Long running)
- Go to https://www.runpod.io/console/pods
- Pick SECURE CLOUD or COMMUNITY CLOUD and pick GPU, etc.
- For TEMPLATE, type
docker-diffusers-api - Container disks, 5GB, Volume Disk, depends on # of models.
- Finish up, click on the link to “My Pods” and watch the setup complete.
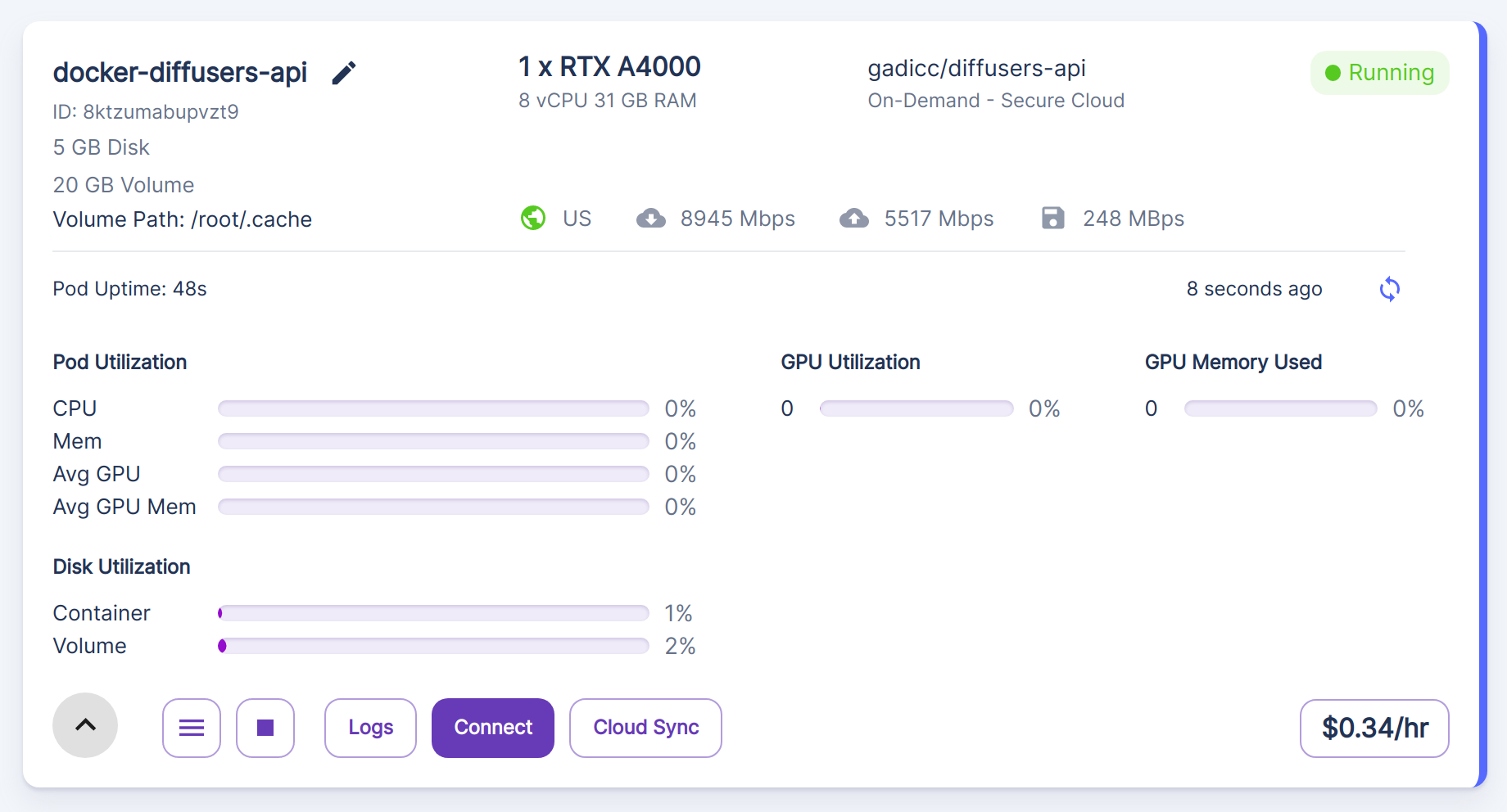
Using / testing
- Click on CONNECT above, Connect via HTTP, and copy the URL, like
https://8kfzumcyzpvzt9-8000.proxy.runpod.net/.
$ export TEST_URL="https://8kfzumcyzpvzt9-8000.proxy.runpod.net/"
$ python test3.py txt2img \
--call-arg MODEL_ID="stabilityai/stable-diffusion-2-1-base"
--call-arg MODEL_PRECISION="fp16"
--call-arg MODEL_URL="s3://"
Running test: txt2img
{
"modelInputs": {
"prompt": "realistic field of grass",
"num_inference_steps": 20
},
"callInputs": {
"MODEL_ID": "stabilityai/stable-diffusion-2-1-base",
"MODEL_PRECISION": "fp16",
"MODEL_URL": "s3://"
}
}
# Note: this includes downloading the model for the first time
# "Inference" includes loading the model for the first time
Request took 43.6s (init: 0ms, inference: 6.3s)
Saved /home/dragon/www/banana/banana-sd-base/tests/output/txt2img.png
{
"$meta": {
"PIPELINE": "StableDiffusionPipeline",
"SCHEDULER": "DPMSolverMultistepScheduler"
},
"image_base64": "[512x512 PNG image, 429.0KiB bytes]",
"$timings": {
"init": 0,
"inference": 6251
},
"$mem_usage": 0.7631341443491532
}
# 2nd request onwards (or restart pod after volume download)
Request took 4.6s (inference: 2.4s)
TODO, links to how model cache works, S3-compatible storage, etc.